Most people have no clue what an AI token costs under the hood. They pay $20 a month for ChatGPT, get “unlimited” access, and default to the most powerful model. That’s fine, until you’re the one footing the bill for millions of requests at the MLS or brokerage scale.
That’s when reality hits.
The True Cost of “Smart”
Imagine one AI agent running 1,000 requests a month. That’s roughly 20 million tokens if we average 20,000 tokens per request. Let’s assume out of the 20k requests, 15k are input, 5k output, and assume 30% of the input is cached.
Using a consumer AI model (LLM) like ChatGPT, Grok, Claude, or Gemini, that’s invisible. At enterprise scale, it’s a budget line item that can add up.
Monthly Cost Breakdown by Model (1,000 Requests)
NOTE: Costs displayed are at the time of publishing this article
|
Model |
Input (10.5M) | Cached Input (4.5M) | Output (5M) |
Total Monthly Cost |
|
GPT-5.2 |
$18.38 | $0.79 | $70.00 |
$89.17 |
|
GPT-5.1 |
$13.13 | $0.56 | $50.00 |
$63.69 |
|
GPT-5 Mini |
$2.63 | $0.11 | $10.00 |
$12.74 |
|
GPT-5 Nano |
$0.53 | $0.02 | $2.00 |
$2.55 |
|
GPT-4.1 |
$21.00 | $2.25 | $40.00 |
$63.25 |
|
GPT-4.1 Mini |
$4.20 | $0.45 | $8.00 |
$12.65 |
Tokens Per Request Example
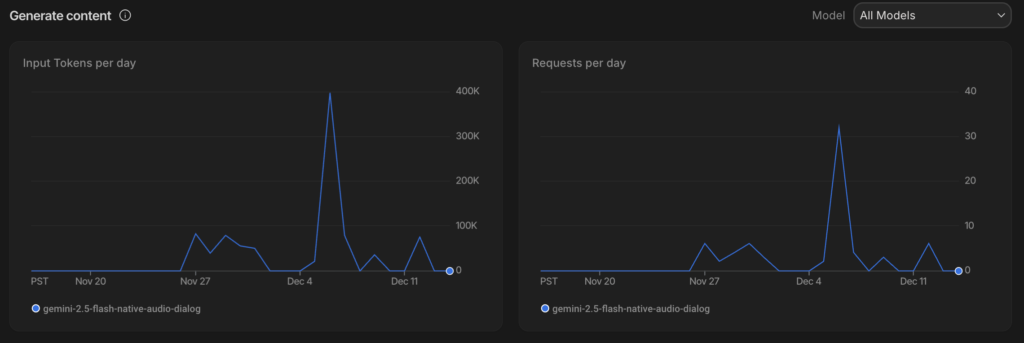
To put the requests-to-tokens relationship in perspective, I recently spent 10 days building a voice-first AI experience to put several large models through their paces.
My goal? Cut through the hype and see, firsthand, how quality stacks up against cost when you move beyond the demo phase. The Gemini 2.5 Flash Native Audio Dialog model, in particular, offered some eye-opening insights.
Since this was strictly a proof-of-concept, I ran everything on a free-tier account.
Shoutout to Google for offering real features and generous limits, even at zero cost.
For this article, I’m focusing on request and input tokens only (output tokens still hit your wallet if you scale up).
In just ten days, input usage topped 910,000 tokens across only 58 requests. The prompts? Nothing wild—just standard test queries. Still, that averages out to a whopping 15,700 tokens per request.
If this hadn’t been on a free plan, input alone would’ve cost me just under thirty cents. That’s pocket change for solo testing in your spare time.
But scale that up. Say, you’re running 20 sessions, 100 requests a day. At 15,700 tokens per request, you’re suddenly looking at 31.4 million tokens daily, almost 1 billion a month. At $0.50 per million tokens, input alone could set you back $471 each month.
Most AI Tasks Don’t Need a Ferrari
Let’s be blunt! Most tasks that MLSs and brokerages want to automate are routine, high-volume, and perfect for Nano or Mini models. Here at WAV Group, when we develop your AI applications, we build in optionality that enables you to associate the least expensive LLM model for the best result.
For example, when normalizing data across thousands of listing entries each day, the task is predictable and structured. An ideal fit for a low-cost model that can handle field validation and correction with speed and consistency.
When running listing audits to identify missing photos, incorrect room counts, or inconsistent property descriptions, there is no need for deep reasoning. All that is needed is fast, scalable text and image processing.
In member support Q&A systems, most questions concern office hours, login issues, or rule clarifications. A mini model can easily achieve high accuracy on those tasks using a knowledge base or fine-tuned embeddings. Deep reasoning is not required to look up a fact.
Filling out forms based on prior responses or public record lookups is another area where a simple agent can shine. The task is structured, repetitive, and also does not need advanced reasoning.
Even internal search across MLS documents, training guides, or help desk archives can be handled effectively with lightweight embedding and retrieval workflows, keeping costs down while improving access to institutional knowledge.
None of those need a GPT-5.2 model that costs nearly $90 per month per agent for just 1,000 requests. What enterprise brokers and MLSs should know is that you can save your agents lots of licensing fees by delivering AI at scale rather than each of them paying for one or more LLM products.
Reserve Premium Models for High-Stakes Work
There are moments when you do want the Ferrari.
When interpreting new or evolving regulations that impact brokerage operations, accuracy and nuance are critical. A premium model can absorb complex legal phrasing and return contextual summaries that support compliance efforts.
If you’re drafting emails, press releases, or official statements on sensitive topics, such as fair housing violations or legal disputes, a top-tier model helps strike the right tone while ensuring consistency and professionalism.
When creating polished content for executive presentations or investor updates, nuance and clarity matter more than speed. A higher-end model can improve grammar, align with tone, and provide suggestions that elevate the narrative.
Strategic generation is another high-value use case. If you’re feeding in a mix of market data, internal KPIs, and partner feedback to surface trends or recommend direction, you want a model that can reason across unstructured inputs and still deliver an actionable output.
Reserve premium models for these use cases, and deploy them only when it matters most.
What Consumer AI Gets Wrong
Consumer AI trains people to think “always use the best.” You never get throttled. You never see a bill. There’s no feedback loop.
But enterprise AI? You’ve got to think like an operator. Every model call has an impact. Every task needs to justify its cost.
Consumer AI isn’t the only game in town. You can self-host SLMs and LLM models either on-premises or in the cloud, or you can spin up GPU cycles on demand. Better yet, you can fine-tune these models to reflect your company’s tone, governance, and culture, shaping them to fit your business like a glove to bring cost efficiency in running them. Moreover, you can connect AI to useful tools that are already in your tech stack – from basic things like sending an email, setting a calendar appointment, building a presentation, to more complex activities like setting up a saved search or drafting an agreement. See CompassAI for examples.
There’s a whole world beyond plug-and-play APIs, and we’ll dig deeper into these strategies in future articles.
The Operational Playbook
If you’re serious about building AI into your operations, you need to approach it strategically.
First, architect your systems for flexibility. Don’t assume one model fits every need. Design workflows that can route tasks to different models based on complexity, urgency, and cost sensitivity.
Second, automate your cost intelligence. Set up dashboards or logging systems that show exactly how many tokens are being used, by whom, and for what types of tasks. This visibility helps you optimize spending and improve the accuracy and efficiency of your AI models.
Third, segment your tasks thoughtfully. High-volume, low-risk operations should run on cheaper models. Save the expensive models for when they’re truly needed.
And finally, think like a product manager. Each model call is not just a utility, it’s a feature with costs, risks, and returns. Evaluate it that way.
And above all, treat AI as a managed cost center. Because if you don’t, it’ll quietly eat your margin alive and profits will fly away.
If you plan to get started with AI in 2026, or you would like to roadmap your expansion of AI use in your brokerage or MLS, we are ready advisors and can either supervise or perform your development. At WAV Group, you always own your AI.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}